Classification problems are widespread and of great practical importance. In this article, we will show how symbolic regression can be used to solve this kind of problem.
Classification problems
Currently, the most commonly used machine learning method for classification are likely neural networks and their variants, including for instance convolutional neural networks (CNN) for image classification.
Numerically, the problem is quite simple. The goal is to have a mathematical operator that returns a different integer number based on the category:
f(input variables) = 0 or 1 or 2
Symbolic regression: how to use it for classification?
Since the output of the classification model needs to be an integer number, a custom symbolic regression search must be employed.
One way to ensure that the formula will return integer numbers only is to search for f(x) such that y = round(f(x)):
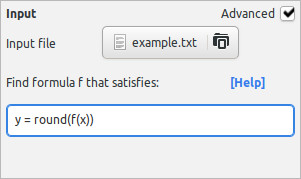
This way, the symbolic regression search will not have to waste time on functions that return floating-point values.
Which error metric to use?
For meaningful optimization in the context of a classification problem, two main search metrics should be used: Classification accuracy or F1 score.
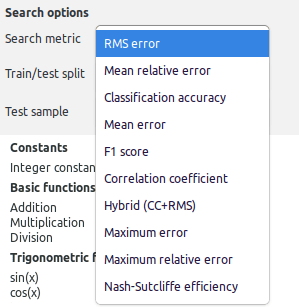
If the categories are more or less equally likely, classification accuracy is the best choice. But if the category is 0 in nearly all cases and 1 only for a few exceptions, the F1 score is a more appropriate choice.
What if I have several categories?
This is not a problem. Just represent the different categories as different integer numbers: 1 for the first category, 2 for the second one, and so on.
In practice, you are going to have to prepare an input file that will look like this:
input1 input2 input3 classification
0.10456 0.86774 0.64066 1
0.04537 0.23525 0.60929 3
0.01393 0.74641 0.28997 1
0.26839 0.20967 0.04693 2
0.02682 0.90024 0.65051 3